Fig. 4
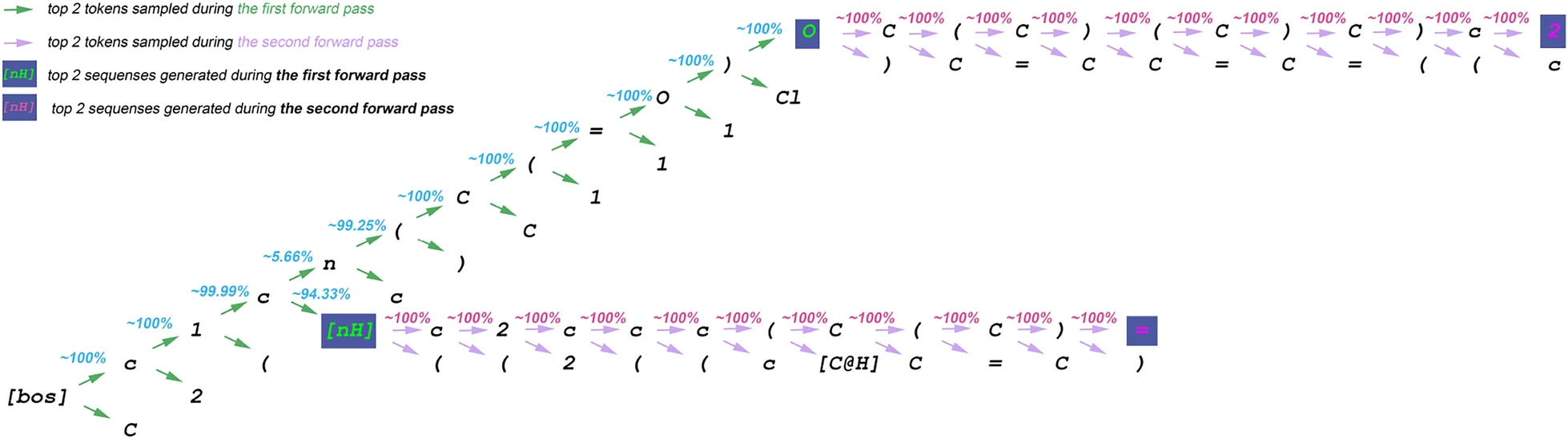
An example of two first iterations of the sampling of candidate sequence trees in our speculative beam search with two generated sequences maintained for one query sequence in the batch. Here, we select the two best candidates at each iteration. The draft length D in this example is 10. The best draft for the first iteration is c1cn(C(=O). It gets concatenated with the BOS token. The first forward pass generates 12 candidate sequences. The best sequences in the first iteration are c1c[nH] and c1cn(C(=O)O, and they become the “beams”. In the second iteration, the best draft for the first “beam” is c2ccc(C(C), and for the second one it is C(C)(C)C)c. The second forward pass generates 24 sequences overall, which all get sorted by their probabilities. The most probable sequences after the second iteration are c1c[nH]c2ccc(C(C)= and c1cn(C(=O)OC(C)(C)C)c2, and they become the generated sequences for the next iteration. In this example, after two iterations SBS generates two sequences of lengths 15 and 22, respectively, whereas the standard beam search would have generated two sequences of length 2